
Beim Einsatz großer Sprachmodelle (Large Language Models, LLMs) für die strukturierte Dokumentenerstellung leiden häufig Genauigkeit und Kohärenz. Dieser Beitrag stellt einen Multi-Agent-Workflow vor, der diese Einschränkungen adressiert.
In unserem kürzlich erschienenen Artikel „Was ist Agentic AI“ haben wir erläutert, wie agentenbasierte Systeme es großen Sprachmodellen ermöglichen, zu planen, zusammenzuarbeiten und autonom zu handeln. Aufbauend auf dieser Grundlage wenden Multi-Agent-Sprachmodelle diese Fähigkeiten auf die strukturierte Dokumentenerstellung an:
In Branchen, die auf komplexe Dokumentation angewiesen sind – etwa klinische Zusammenfassungen, regulatorische Einreichungen oder technische Berichte – verbringen Fachleute Stunden damit, Informationen zu sammeln, Strukturen zu entwerfen und Formulierungen zu verfeinern, bevor überhaupt ein nutzbarer Entwurf entsteht. Während herkömmliche LLMs flüssige Absätze generieren können, haben sie oft Schwierigkeiten, Struktur beizubehalten, Fakten korrekt wiederzugeben und Ideen über lange Dokumente hinweg konsistent zu transportieren.
In diesem Artikel stellen wir ein Multi-Agent-Framework vor, das diese Einschränkungen überwindet, indem es den Generierungsprozess in spezialisierte KI-Agenten aufteilt, die Inhalte planen, entwerfen, prüfen und gemeinsam verfeinern. Das Ergebnis? Gut strukturierte Entwürfe, die auf echten Daten basieren und es Fachleuten ermöglichen, vom ersten Konzept bis zum prüfungsreifen Dokument in einem Bruchteil der bisherigen Zeit zu gelangen.
Unser System folgt einem modularen Multi-Agent-Workflow, bei dem spezialisierte Agenten unterschiedliche Phasen der Dokumentenerstellung übernehmen – von der Informationsbeschaffung über das Narrative Design bis zur finalen Zusammenstellung. Jeder Agent agiert auf einer bestimmten Abstraktionsebene: entweder (F)okussiert auf Details und einzelne Abschnitte oder mit einer (H)olistischen Sicht auf Struktur und Kohärenz.
Der Prozess beginnt mit dem Benutzer, der Quelldokumente hochlädt und die Erstellung eines Dokuments vom Typ X zu Thema Y anfordert. Das System durchläuft anschließend folgende Schritte:
Gemeinsam bilden diese Agenten ein geschichtetes System, das die Arbeitsweise erfahrener Autor:innen nachbildet (siehe Abbildung 1). In den folgenden Abschnitten betrachten wir die Schlüsselagenten dieses Prozesses näher.
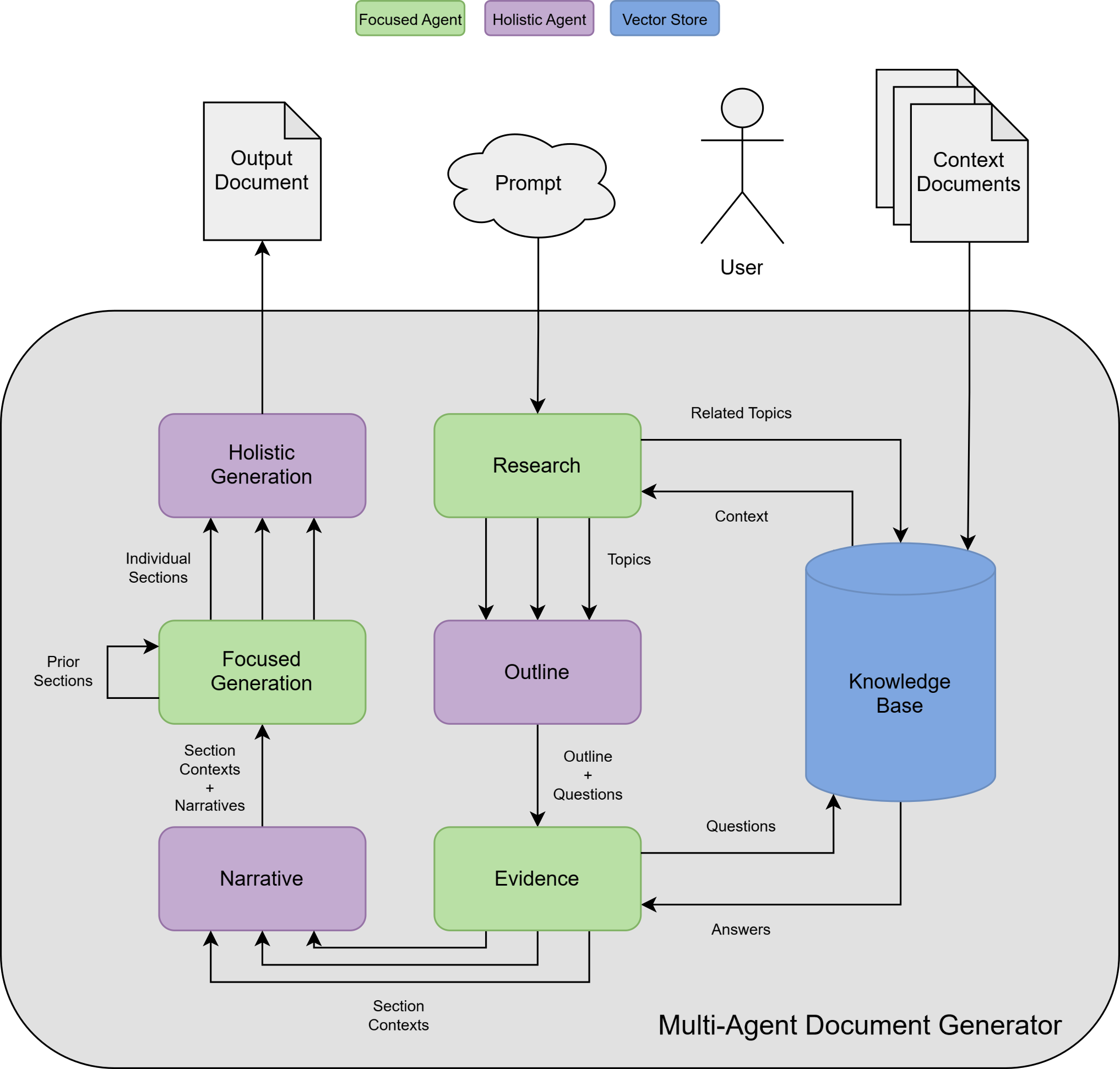
(Abbildung 1: Eine Übersicht über den agentenbasierten Workflow der Dokumentgenerierung)
Wenn wir komplexe Dokumente schreiben, beginnen wir selten sofort mit dem Tippen. Wir sammeln zunächst Fakten und führen Recherchen durch, um sicherzustellen, dass nichts Wesentliches fehlt. Dann konsolidieren wir unser Wissen, planen die Struktur des Dokuments und entscheiden, wie die Themen miteinander verknüpft werden. Schließlich überprüfen wir beim Schreiben jedes Detail, um Daten und Referenzen zu sichern. Diese drei Phasen sind für uns so selbstverständlich, dass wir sie kaum bemerken – und doch bestimmen sie, was ein vollständiges, kohärentes und korrektes Dokument ausmacht.
Große Sprachmodelle folgen diesem Prozess jedoch nicht von Natur aus. Sie sind leistungsfähige Textgeneratoren, die flüssige Absätze produzieren können, aber sie kämpfen mit drei zentralen Anforderungen, die für zuverlässige Dokumentenerstellung entscheidend sind:
Unser Multi-Agent-Framework begegnet diesen Anforderungen mit drei spezialisierten Komponenten: dem Research-, Outline- und Evidence-Agenten.
Bevor ein Dokument geschrieben werden kann, muss das Sprachmodell verstehen, was das System weiß – und was nicht. Der Research Agent ist der erste Schritt des Systems bei der Beantwortung einer Benutzeranfrage (z. B. „Schreibe einen Artikel über Thema X“). In dieser Phase besteht das Hauptziel des Agenten darin, ein strukturiertes Verständnis sämtlicher verfügbarer Informationen aufzubauen.
Er beginnt, indem er die Vektordatenbank abfragt, um relevante Informationsausschnitte zu finden, die anschließend mithilfe semantischer Ähnlichkeit in zusammenhängende Unterthemen gruppiert werden. Jedes Unterthema wird zusammengefasst und mit den entsprechenden Belegen verknüpft, wodurch eine strukturierte Übersicht über die Wissenslandschaft entsteht. Um Wissenslücken zu identifizieren, vergleicht der Agent die gefundenen Unterthemen mit einer allgemeinen Liste erwarteter Themen. Das Ergebnis ist eine priorisierte Karte des vorhandenen Wissens – eine Grundlage, die den nachfolgenden Agenten bei der inhaltlich fundierten Generierung hilft.
Ohne eine strukturierte Recherchephase würde das Modell versuchen, über Themen zu schreiben, die im Allgemeinen relevant sind, aber in der Wissensbasis gar nicht vorkommen – und gleichzeitig wichtige vorhandene Bereiche übersehen. Das Ergebnis wäre ein unvollständiges Dokument, angereichert mit halluziniertem Inhalt, wo Präzision gefordert ist, und lückenhaft, wo Details nötig wären.
Sobald das Modell weiß, welche Informationen existieren, muss es entscheiden, wie diese organisiert werden sollen. Der Outline Agent übernimmt das Strukturieren des Dokuments, indem er einen hierarchischen Plan erstellt, der festlegt, welche Abschnitte und Unterabschnitte das Dokument enthalten soll, wie sie zusammenhängen und in welcher Reihenfolge sie erscheinen.
Der Agent benennt jedoch nicht nur Abschnitte – er weist jedem Unterabschnitt gezielte Leitfragen zu. Diese Fragen dienen als Ziele für spätere Agenten und geben vor, was jeder Teil des Dokuments vermitteln soll. Das spiegelt die Arbeitsweise menschlicher Autor:innen wider, die Inhalte nicht nur gliedern, sondern für jeden Abschnitt auch die zentralen Ideen festlegen, die behandelt werden sollen.
In der Praxis erfüllt dieser Schritt dieselbe Funktion wie die Reasoning-Komponente eines ReAct-Moduls – einer Methode, die nachweislich die Leistung von Sprachmodellen verbessert, indem sie das Denken („Worüber soll ich schreiben?“) vom Schreiben („Wie soll ich es formulieren?“) trennt. Dadurch kann jeder Abschnitt isoliert generiert werden, ohne den Gesamtzusammenhang zu verlieren.
Indem der Outline Agent sowohl eine Makrostruktur (Kapitelaufbau) als auch Mikroführung (Leitfragen) etabliert, stellt er sicher, dass die inhaltliche Linie von Anfang bis Ende konsequent erhalten bleibt.
„Halluzinationen“ also die Neigung von Sprachmodellen, erfundene „Fakten“ zu erzeugen sind wahrscheinlich das bekannteste Problem beim Einsatz von LLMs. Während dies bei kurzen Alltagsantworten tolerierbar sein mag, ist es in hochkritischen Anwendungsfällen wie regulatorischen Texten, klinischen Studien oder Vertragswerken inakzeptabel.
Der Evidence Agent minimiert dieses Risiko, indem er den Generierungsprozess eng mit einer überprüften Wissensbasis verknüpft. Er nutzt Retrieval Augmented Generation (RAG), um die relevantesten Passagen für jeden Abschnitt gemäß dem vom Outline Agent erstellten Plan abzurufen. Diese Abrufe erfolgen dynamisch und werden durch den Kontext des jeweiligen Unterthemas gesteuert, sodass jede generierte Aussage auf eine konkrete Quelle zurückgeführt werden kann.
Das Ergebnis ist ein schreibprozess, der belegbasiert und referenzbewusst ist: Dadurch werden nicht nur faktische Richtigkeit und Nachvollziehbarkeit gewährleistet, sondern auch Transparenz – ein entscheidender Faktor für Prüfungen, Audits und Compliance-Anforderungen.
Selbst wenn alle Fakten vorliegen und eine klare Gliederung existiert, ist die eigentliche Schreibarbeit noch lange nicht abgeschlossen. Als menschliche Autor:innen schaffen wir einen roten Faden, passen die inhaltliche Tiefe an den Kontext an und verfeinern die Sprache, um ein konsistentes und ansprechendes Dokument zu erstellen.
LLMs hingegen agieren nicht von Natur aus auf dieser Abstraktionsebene. Ohne gezielte Steuerung haben sie mit drei zentralen Herausforderungen in den späteren Phasen der Dokumentenerstellung zu kämpfen:
Unser System begegnet diesen Herausforderungen mit drei weiteren Agenten, die auf den strukturellen, stilistischen und narrativen Ebenen des Schreibprozesses arbeiten: dem Narrative-, Focus- und Holistic-Agenten.
Dokumente sind mehr als die Summe ihrer Teile. Selbst wenn einzelne Abschnitte faktisch korrekt und in sich schlüssig sind, kann ein Dokument unzusammenhängend wirken, wenn es keine übergreifende Argumentationslinie oder Geschichte aufbaut.
Der Narrative Agent löst dieses Problem, indem er die Abhängigkeiten zwischen den Abschnitten analysiert. Basierend auf der Gliederung und den Leitfragen erstellt er ein narratives Gerüst, das den Informationsfluss im gesamten Dokument steuert – also festlegt, welche Konzepte früh eingeführt und welche erst im Verlauf weiterentwickelt werden sollen.
Dieser Schritt spiegelt einen zentralen Aspekt menschlichen Schreibens wider: Inhalte werden nicht nur thematisch geordnet, sondern als fortlaufende Argumentation, Erklärung oder Erzählung strukturiert. Ohne den Narrative Agenten würde eine solche Kohärenz – wenn überhaupt – nur zufällig entstehen.
Wenn ein Sprachmodell ein ganzes Dokument in einem Durchgang generiert, neigt es dazu, wichtige Details zu übersehen. Die Abschnitte bleiben oberflächlich, und spezifische Punkte werden nur unzureichend ausgearbeitet.
Um das zu vermeiden, nutzt unser System die Leitfragen, den abgerufenen Kontext und die narrativen Vorgaben, um das Dokument Abschnitt für Abschnitt zu erzeugen. So erhält jeder Teil die nötige Aufmerksamkeit und Tiefe.
Diese abschnittsweise Generierung bringt jedoch ein neues Problem mit sich: Redundanzen. Ohne Bewusstsein für den umgebenden Inhalt neigen Modelle dazu, Einleitungen zu wiederholen, dieselben Fakten erneut zu nennen oder ähnliche Formulierungen mehrfach zu verwenden.
Der Focus Agent ist daher kontextbewusst – er berücksichtigt die bereits generierten Abschnitte während des Schreibens und passt sich entsprechend an. Das Ergebnis sind detaillierte, eigenständige Abschnitte mit minimalen Wiederholungen und klarer thematischer Progression.
Der Nachteil der abschnittsweisen Generierung ist ein häufig uneinheitliches Gesamtergebnis: Übergänge wirken holprig, der Tonfall variiert, und feine Redundanzen bleiben bestehen. Das entspricht im Grunde einem ersten Rohentwurf – vollständig, aber noch nicht geschliffen.
Wie menschliche Autor:innen ihren Entwurf überarbeiten, übernimmt der Holistic Agent eine abschließende Durchsicht des gesamten Dokuments. Er glättet Übergänge, vereinheitlicht Ton und Stil und behebt Inkonsistenzen, die entstehen, wenn Teile unabhängig voneinander verfasst wurden.
Wesentlich ist auch, dass dieser Agent die Sprache und den Stil an die Absicht des Nutzers anpasst – ob formell, technisch oder erzählerisch. Zudem erstellt er Einleitung und Schluss, um das Dokument mit einem klaren Ziel und Fazit zu rahmen.
Das Ergebnis ist kein zusammengeflickter Text, sondern ein einheitlicher, durchdachter Entwurf, der inhaltlich, sprachlich und strukturell überzeugt.
Während heutige große Sprachmodelle (LLMs) in der Lage sind, flüssigen Text zu generieren, scheitern sie oft daran, lange, strukturierte und faktenbasierte Dokumente zu erstellen.
Unser Multi-Agent-Framework begegnet diesen Schwächen, indem es den Schreibprozess in spezialisierte Phasen aufteilt und so die Arbeitsweise erfahrener Autor:innen nachbildet.
Durch die Kombination aus gezielter Recherche, strukturierter Planung, evidenzbasierter Generierung und ganzheitlicher Überarbeitung liefert das System hochwertige Entwürfe, die kohärent, vollständig und überprüfbar sind.
In dokumentenintensiven Bereichen, in denen Genauigkeit, Klarheit und Effizienz entscheidend sind, verwandelt dieser Ansatz Sprachmodelle von generischen Textgeneratoren in zuverlässige Schreibassistenten.
