In den letzten Jahren haben sich die Fähigkeiten großer Sprachmodelle (Large Language Models, LLMs) kontinuierlich weiterentwickelt, und ihre Anwendungsbereiche haben sich stetig erweitert. Diese Vielseitigkeit wurde durch das Fine-Tuning großer Foundation-Modelle auf spezifische Aufgaben (z. B. Instruktionsbefolgung) oder Domänen (z. B. juristische Texte) erreicht. Diese Modelle zeigen eine hervorragende Leistungsfähigkeit bei der Erzeugung strukturierter Ausgaben wie Code, JSON oder SQL. Der Fokus dieses Artikels liegt auf einem praxisnahen Business-Beispiel im Kontext von Text-to-SQL.
In modernen Organisationen werden große Mengen an geschäftlichen und proprietären Daten in relationalen Datenbanken gespeichert, deren effizienter Zugriff häufig geschultes Personal sowie ein gutes Verständnis von Datenstrukturen und Datenmanagementprinzipien erfordert. Viele Mitarbeitende, die mit diesen Daten arbeiten müssen, verfügen jedoch nicht über ausreichende SQL-Kenntnisse, was eine effiziente Datennutzung erschwert. Ein typisches Szenario aus der Praxis könnte wie folgt aussehen: Die Marketingabteilung eines Unternehmens benötigt die Verkaufszahlen von Produkt A aus dem vergangenen Jahr für alle Niederlassungen in Hamburg und Berlin.
Genau an diesem Punkt setzen Text-to-SQL-Systeme an, indem sie die Lücke zwischen in natürlicher Sprache formulierten Anfragen und der Extraktion von Informationen aus relationalen Datenbanken schließen. Die Qualität, die heutige LLMs erreichen, macht die Generierung von SQL zu einem verlässlichen Prozess (siehe beispielsweise Referenz [1] als aktuelle Übersicht). In den beschriebenen Geschäftskontexten sehen wir daher eine hohe Relevanz für Text-to-SQL-Systeme, die einerseits eine benutzerfreundliche Oberfläche mit natürlichen Spracheigenschaften kombinieren und gleichzeitig den Zugriff auf eine Vielzahl bestehender Datenbanken ermöglichen, darunter Data Warehouses oder Data Marts.
In diesem Blogbeitrag fassen wir unsere Erkenntnisse aus der Entwicklung und dem Testen eines standardisierten Text-to-SQL-Anwendungsfalls auf Basis einer Verkaufsdatenbank zusammen. Wir beschreiben die Bausteine, aus denen das Gesamtsystem besteht, gehen vertieft auf das entsprechende Prompt Engineering ein und skizzieren einen typischen Konversationsablauf. Dabei hat sich gezeigt, dass der Einsatz eines leistungsfähigen LLMs in der Nutzeranwendung zur SQL-Generierung eine Interaktion mit der Datenbank auf verschiedenen Ebenen ermöglicht:
L0: Die unmittelbare Ebene.
Die Nutzeranfrage bezieht sich auf Fragen zum Datenbankschema oder zu rohen Tabelleninhalten. Beispiele sind:
„Zeige mir das aktuelle Datenbankschema“ oder „Gib alle Werte der Spalte ‚brand‘ zurück“.
L1: Die Abfrageebene.
Dies ist die Konversationsebene, die für Anwendungsfälle besonders relevant ist, bei denen konkrete Informationsabfragen auf Basis des Schemas gestellt werden. Ein Beispiel:
„Zeige mir alle Produktnamen in der Kategorie ‚Kosmetik‘, die Kunden aus Hamburg im letzten Monat gekauft haben.“
Durch die Kombination von Informationen aus dem Datenbankschema mit den Abfragebegriffen ist das LLM in der Lage, die entsprechende SQL-Anweisung zu generieren, die anschließend von einem Orchestrator an die Abfrage-Engine weitergeleitet wird. In der resultierenden Abfragezeichenkette unseres Produkt-A-Beispiels werden unter anderem die Tabellen und Spalten ‚customer‘, ‚category‘, ‚product.name‘, ‚customer.address‘ und ‚sales.date‘ zusammen mit den erforderlichen Joins und Quantifizierungen adressiert.
L2: Die referenzielle Ebene.
Ein zentraler Vorteil des konversationellen Gedächtnisses liegt in der Möglichkeit, frühere Abfragen einfach zu referenzieren, sodass die gesamte Anfrage nicht erneut eingegeben werden muss, wenn nur geringfügige Anpassungen erforderlich sind. Kehren wir zu dem obigen Beispiel zurück: Die gleichen Informationen bezüglich Kategorie und Zeitraum werden benötigt, diesmal jedoch für die Niederlassung in Berlin. Die Eingabe „Wiederhole die letzte Abfrage für unsere Berliner Niederlassung“ genügt.
Abhängig von der Länge des Konversationsfensters und der Komplexität der Abfragen ist eine Interaktion mit der Datenbank auf SQL-Ebene in Dialogform möglich.
Kommunikation vom Typ L2 findet auch dann statt, wenn Nutzende Feedback geben, um generierten SQL-Code zu steuern oder zu korrigieren. Durch die Berücksichtigung verschiedener Datenbankdialekte kann sich das LLM gut an die Besonderheiten eines Datenbanksystems anpassen, dennoch können Fehler im Generierungsprozess auftreten. Sobald ein Problem durch strikte Syntax- und Formatprüfungen erkannt wird, kann ein Korrektur-Prompt bereitgestellt und durch eine Linter-Ausgabe ergänzt werden, etwa:
„In deiner letzten Abfrage liegt folgendes Problem vor: <Linter-Ausgabe>. Versuche, es zu korrigieren.“
Dieser Ansatz hat in den seltenen Fällen, in denen Syntax- oder Formatierungsprobleme auftraten, gut funktioniert. In einer produktiven Umgebung sollten Nutzende jedoch nicht mit der Wiedergabe von SQL-Korrekturen konfrontiert werden. Während der Entwicklungsphase half jedoch eine sorgfältige Analyse der Linter-Ausgaben dabei, den System-Prompt, die Schema-Linking-Strategie und die Postprocessing-Schritte zu verfeinern. Bei komplexeren Datenbankschemata oder hochkomplexen Abfragen wird diesen Aspekten eine noch größere Bedeutung zukommen.
Zusammenfassend lässt sich sagen, dass durch den Einsatz leistungsfähiger LLMs in SQL-getriebenen Geschäftsanwendungen Informationen über Text-to-SQL-Systeme leicht zugänglich werden und dadurch eine effiziente Erkenntnisgewinnung, eine höhere Datenautonomie sowie eine bessere Ressourcennutzung ermöglicht wird.
Unser Ziel ist es zu zeigen, wie ein robuster und erweiterbarer Text-to-SQL-Workflow aufgebaut werden kann – beginnend bei einer Nutzeranfrage über die SQL-Generierung und -Validierung bis hin zur Bereitstellung der entsprechenden Datenbankergebnisse. In realen Kundenprojekten gelten dabei in der Regel folgende Rahmenbedingungen:
Die folgende Abbildung skizziert den Workflow.
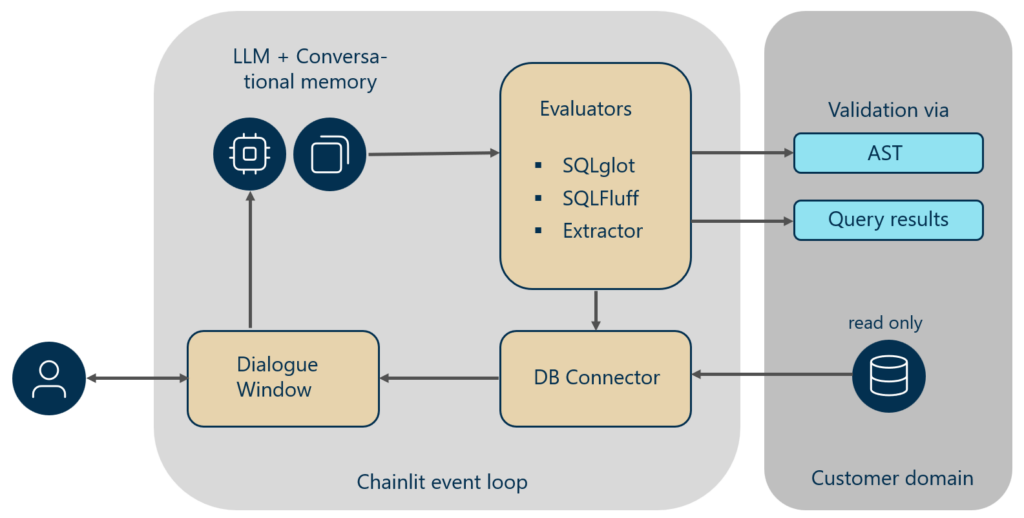
End-to-End-Workflow von der natürlichen Sprachabfrage bis zur validierten SQL-Ausführung
Der Nutzer auf der linken Seite der Abbildung interagiert kontinuierlich mit dem System über ein Dialogfenster, in das Prompts eingegeben und Ergebnisse zurückgespielt werden. Das konversationelle Gedächtnis verfolgt sowohl die Nutzeranfragen als auch die generierten SQL-Abfragen, sodass eine Konversation auf L2-Ebene möglich ist. Bei jeder Abfrage erhält das LLM den System-Prompt zusammen mit dem bisherigen Gesprächsverlauf. Spezifische Informationen wie Datenbankschema, Datenbanktyp und SQL-Dialekt werden beim Systemstart in den System-Prompt eingefügt. In unserer Implementierung werden Validierungsmeldungen der Syntaxprüfer und Linter ebenfalls zu Kontroll- und Debugging-Zwecken zurückgespielt. Sobald die SQL-Abfrage alle Prüfungen bestanden hat, werden der AST und die abgerufenen Daten gespeichert, um eine zusätzliche Verifikation mit einem kundenseitigen Goldstandard zu ermöglichen.
Nach längeren Konversationen ist es empfehlenswert, das konversationelle Gedächtnis zu leeren, um mögliche Verzerrungen zu vermeiden, die sich in einer Kette von Abfragen aufgebaut haben könnten. Da die Kontextlängen begrenzt sind, verwenden wir ein Konversationsfenster mit einer Länge von 20. Für unsere Demonstration des Geschäftsanwendungsfalls kamen folgende Komponenten zum Einsatz:
Wie bereits erwähnt, ist das Fine-Tuning eines Modells nicht zielführend, wenn es darum geht, schnell in den produktiven Einsatz zu gelangen. Aufgrund der Fähigkeiten heutiger LLMs lässt sich das Modell vielmehr durch durchdachtes Prompt Engineering steuern, das einigen grundlegenden Prinzipien folgt, die im Kontext der SQL-Generierung relevant sind. Wie in [1] beschrieben, lässt sich Prompt Engineering in drei Phasen unterteilen: Preprocessing, Inference und Postprocessing. Beim Aufbau unseres System-Prompts zur Erzielung hoher SQL-Qualität orientieren wir uns weitgehend an diesen Prinzipien, auch wenn einige der in [1] beschriebenen Aspekte auf unseren produktiven Anwendungsfall nicht zutreffen. Im Folgenden skizzieren wir unsere Konstruktionsprinzipien für den LLM-System-Prompt.

Beispiel für LLM-generierte Metadaten zur SQL-Erzeugung
Wie oben beschrieben, bezieht sich Ebene 0 auf Abfragen, die direkt die Datenbankstruktur oder rohe Tabelleninhalte betreffen und manchmal notwendig sind, um spezifische Details der Datenbank offenzulegen.
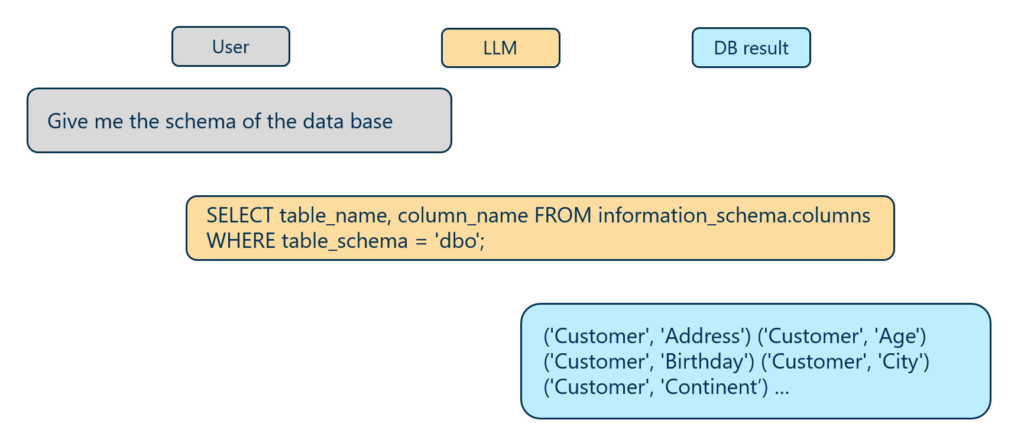
Direkte Schemaabfrage ohne fachliche Datenfilterung
Durch die Aufrechterhaltung des Konversationsverlaufs ist eine kurze Folgefrage möglich, die intern automatisch zur erweiterten Abfrage führt (die Ausgabereihenfolge der Tupel ist dabei beliebig).
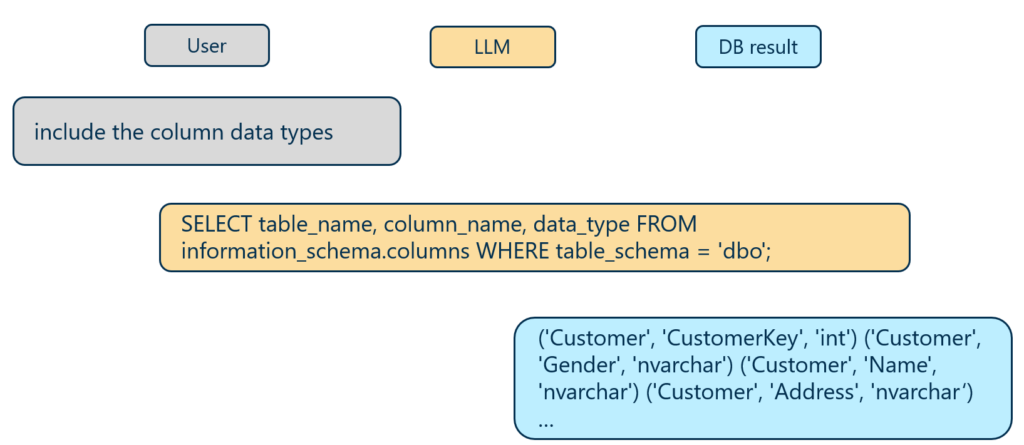
Erweiterung einer bestehenden Schemaabfrage durch Konversationskontext
Als Beispiel für eine reale Abfrage möchten wir Kunden ermitteln, die in einer bestimmten Filiale innerhalb eines bestimmten Zeitraums einen Kauf getätigt haben.

Übersetzung einer fachlichen Fragestellung in eine SQL-Abfrage
Nun wollen wir eine Folgeabfrage ausführen, um die Kunden für die Filiale in Hamburg zu finden, wobei angenommen wird, dass das LLM die fehlenden Informationen aus dem Konversationsgedächtnis ableiten kann.
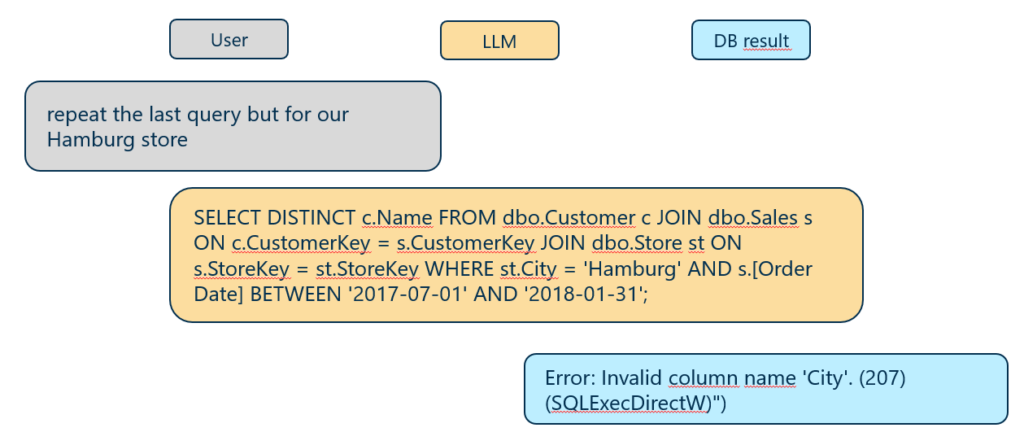
Kontextbasierte Folgeabfrage mit semantischem SQL-Fehler
Interessanterweise wurde hierbei ein Fehler in der erzeugten Abfrage beobachtet (trotz syntaktischer Korrektheit), der darauf zurückzuführen ist, dass angenommen wurde, die Tabelle „Store“ verfüge über die Spalte „City“, was tatsächlich nicht der Fall ist. Hier konkurriert das interne Weltwissen des LLMs – mit hoher Wahrscheinlichkeit die Annahme, dass „Hamburg“ eine Stadt ist – mit den im Schema hinterlegten Informationen, dass keine Spalte „City“ in der Tabelle „Store“ existiert. Aus Sicht der Datenbank erscheint es etwas inkonsistent, Datenpunkte zu „Hamburg“ in der Spalte „Store.State“ zu speichern. Streng genommen ist „Hamburg“ jedoch ein Stadtstaat in Deutschland, was diese Modellierung rechtfertigen kann.
Nachdem das Problem lokalisiert wurde, können wir durch eine explizite Klarstellung, dass „Hamburg“ ein Filialstaat und keine Filialstadt ist, in einer L2-Konversation unmittelbar korrekte Ergebnisse erzeugen (beachten Sie das Auftreten deutsch klingender Kundennamen in den Datenbankergebnissen, was auf die Korrektheit der Daten hinweist).

Fehlerkorrektur einer kontextbasierten SQL-Abfrage durch Nutzerfeedback
Zusammenfassend sind die gezeigten Beispiele nicht sehr komplex, zeigen jedoch, dass eine Interaktion mit einer SQL-Datenbank in natürlicher Sprache innerhalb kurzer Zeit ohne gravierende Hindernisse realisiert werden kann. Intern haben wir zudem erfolgreiche Benchmarks mit komplexeren Abfragen durchgeführt, bei denen beispielsweise verschachtelte SELECTs aus anspruchsvolleren Anfragen in natürlicher Sprache generiert wurden.
Mit Blick auf die Zukunft planen wir:
Unser Text-to-SQL-Beispielprojekt zeigt, dass Abfragen in natürlicher Sprache in Kombination mit soliden Engineering-Prinzipien praktikabel und zuverlässig umgesetzt werden können. Es schlägt die Brücke zwischen menschlicher Intention und strukturierten Daten und ermöglicht es Organisationen, den vollen Wert ihrer Datenbanken über konversationelle Schnittstellen zu erschließen.
[1] L. Shi et al., A Survey on Employing Large Language Models for Text-to-SQL Tasks, arXiv:2407.15186 (2025).
[2] B. Ascoli et al., ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models, arXiv:2407.07313 (2025).
[3] X. Wang et al., Self-Consistency Improves Chain of Thought Reasoning in Language Models, arXiv:2203.11171 (2022).