
When using Large Language Models (LLMs) for structured document generation, accuracy and coherence often suffer. This post introduces a multi-agent workflow that addresses these limitations.
In our recent article, “What is Agentic AI?”, we explored how agent-based systems enable Large Language Models (LLMs) to plan, collaborate and act autonomously. Building on that foundation, Multi-Agent Language Models apply these capabilities to structured document generation:
In industries that rely on complex documentation, such as clinical summaries, regulatory submissions, or technical reports, professionals spend hours gathering information, mapping structure, and refining language before a single usable draft emerges. While traditional LLMs can generate fluent paragraphs, they often struggle to maintain structure, ensure factual accuracy and carry ideas consistently across long documents.
In this article, we introduce a multi-agent framework that addresses these limitations by breaking down the generation process into specialized AI agents that plan, draft, fact-check, and refine content collaboratively. The result? Well-structured drafts grounded in real data that allow professionals to move from initial concept to review-ready documents in a fraction of the time.
Our system follows a modular, multi-agent workflow in which specialized agents handle distinct stages of document generation, ranging from content discovery to narrative design and final assembly. Each agent operates at a specific level of abstraction, either (F)ocused on details and individual sections, or with a (H)olistic view on structure and coherence.
The process is initiated by the user, who uploads source documents and requests the generation of a document of type X on topic Y. The system then proceeds through the following steps:
Together, these agents form a layered system that mirrors the way expert authors plan, research, and write (see Figure 1). In the following sections, we take a closer look at the key agents that drive this process.
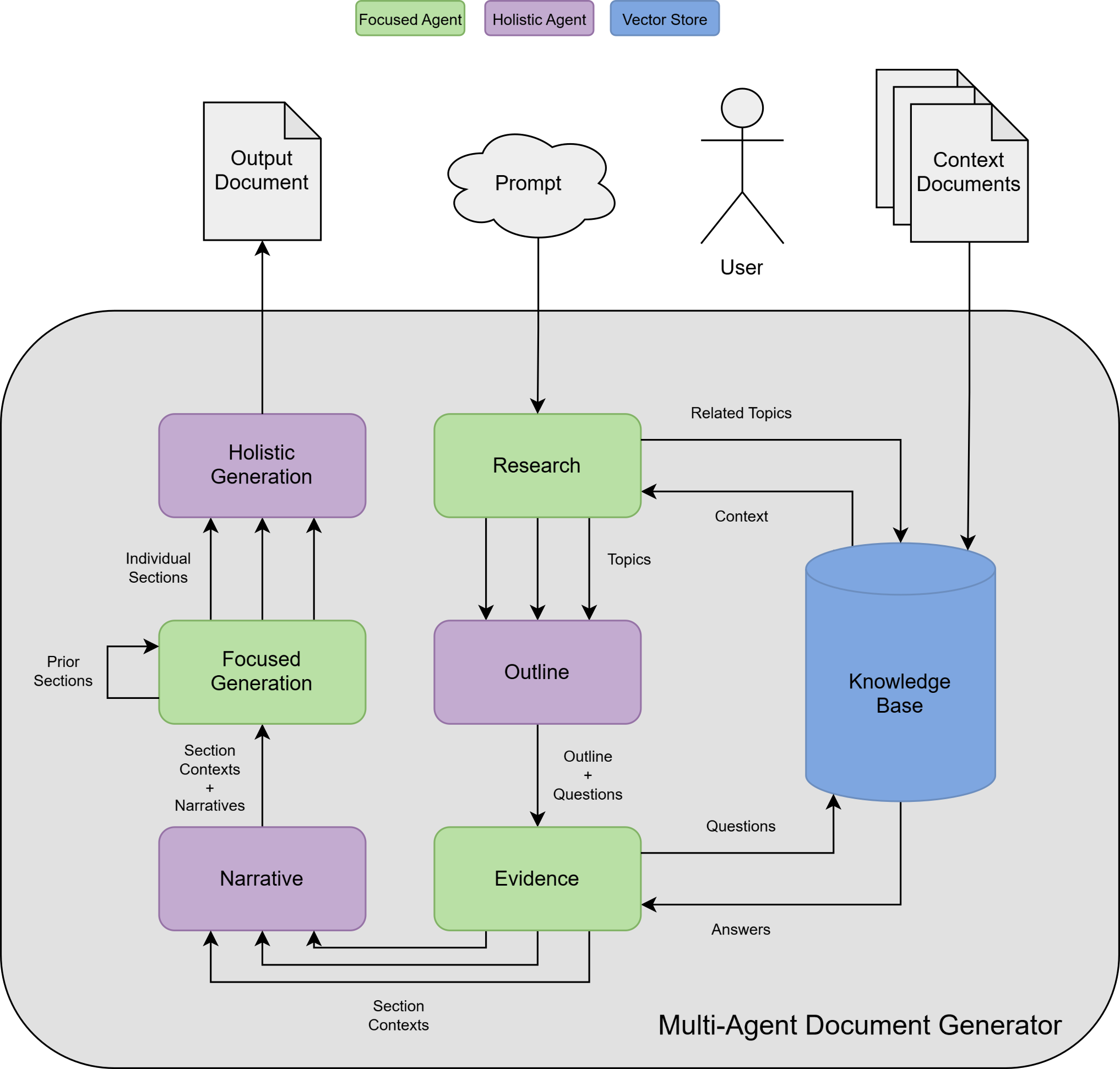
When writing complex documents, we rarely start typing from scratch. We begin by gathering the facts and conducting research to make sure nothing important is missing. Then, we consolidate our knowledge to plan the structure of the desired document, deciding how topics will connect and build on each other. Finally, as we write, we verify every detail, checking data and references to ensure accuracy. These three stages are so natural to us that we hardly notice them, yet they define what makes a document complete, coherent and accurate.
Large Language Models, however, do not inherently follow this process. Out of the box, they are powerful text generators capable of generating fluent paragraphs, but they struggle to meet three essential requirements at the basis of reliable document generation:
Our multi-agent framework addresses these requirements through three dedicated components: The Research-, Outline- and Evidence-Agents.
Before any document can be written, the LLM needs to understand what the system knows, and doesn’t know: The Research Agent is the system’s first step in responding to a user prompt (e.g. “Write an article about topic X”). At this point, the agent’s primary goal is to build a structured understanding of all related information the system has access to.
It starts by querying the vector database to retrieve relevant information chunks, which are then clustered into coherent subtopics using semantic similarity. Each subtopic is summarized and linked to supporting evidence, creating a structured view of the content landscape. To identify knowledge gaps, the agent compares the discovered subtopics against a general-purpose list of expected themes. The result is a prioritized map of what the system knows, providing a high-level foundation that guides subsequent agents in generating content grounded in real evidence.
Without a structured research phase, the model would attempt to write about topics that are relevant in general, but absent from the knowledge base, while conversely overlooking important areas that do exist in the knowledge base. The result would be an incomplete document, padded with hallucinated content where it should be precise, and silent where it should be detailed.
Once the model understands what information exists, it needs to decide how that information should be organized. The Outline Agent reasons about the documents structure by producing a hierarchical plan, thus determining which sections and subsections the document should include, how they relate to one another and in what order they should appear.
Beyond just naming sections, the Outline Agent assigns each subsection a set of guiding questions. These questions act as objectives for later agents, clarifying what each part of the document should explain. This mirrors how human authors plan content: not just by organizing topics, but by identifying the key ideas to explore within them.
In practice, this step performs the same function as the reasoning component of a ReAct module, a method known to improve LLM performance by separating reasoning (“What should I write about?”) from generation (“How should I write it?”). As a result, each section can later be generated in isolation, while still fitting naturally into the overall document. By establishing both a macro-level structure and micro-level guidance through questions, the Outline Agent helps maintain conceptual continuity from start to finish.
Hallucinations, i.e. the tendency of LLMs to invent “facts”, are probably the most well-known challenge in the realm of LLM-based applications. While this may be tolerable for brief, common knowledge answers to everyday questions, it is unacceptable in high-stakes use-cases, such as regulatory text, clinical studies or contractual language.
The Evidence Agent mitigates this risk by tightly coupling the generation process with a verified knowledge base. It leverages Retrieval Augmented Generation (RAG) to retrieve the most relevant passages for each section based on the document plan created by the Outline Agent. This retrieval is performed dynamically, guided by the context of the specific subtopic being written, ensuring that every generated statement can be traced back to a concrete source.
The end result is a writing process that is grounded in evidence and reference-aware: This not only ensures factual correctness but also enhances transparency, which is a critical requirement for audits, reviews, and compliance workflows.
Even when we have all the facts at hand and a clear outline in place, the real work of writing is far from over. As human authors, we craft a narrative, adapt our depth to the context, and refine language to produce a document that is consistent and engaging.
LLMs, however, do not naturally operate at this level of abstraction. Without guidance, they struggle with three core challenges that arise in the later stages of document generation:
Our system addresses these challenges through three additional agents that operate on the structural, stylistic, and narrative layers of the writing process: the Narrative- , Focus-, and Holistic-Agents.
Documents are more than the sum of their parts. Even when individual sections are factually accurate and internally coherent, a document can still feel fragmented if it fails to build a cohesive argument or story across its entire structure.
The Narrative Agent addresses this problem by reasoning about inter-sectional dependencies. Based on the outline and guiding questions, it creates a "narrative scaffolding" that guides the flow of information across the document by deciding which concepts to introduce early and which to evolve throughout the document.
This step captures an important aspect of how human authors write: not just organizing content topically, but structuring the document as an unfolding argument, explanation, or storyline. Without the Narrative Agent, this kind of structure emerges only by accident, if at all.
Generating an entire document in one pass often leads LLMs to gloss over important details. Sections become shallow, and specific points are underdeveloped. To avoid this, our system takes the guiding questions, the retrieved context, and the narrative constraints to generate the document section by section, ensuring each part gets the attention it needs.
This section-wise generation, however, introduces a new problem: redundancy. Without awareness of surrounding content, LLMs tend to repeat introductions, restate the same facts, or duplicate phrasing. To prevent repetition and maintain thematic progression, the Focus Agent is context-aware: it considers prior sections during generation and adapts accordingly, leading to detailed sections while keeping redundancies to a minimum.
The undesirable side product of the exhaustive, section-wise generation approach is a disjointed end-result: Transitions may be rough, tone may drift, and subtle redundancies often remain. It’s the equivalent of a first draft: exhaustive but still unrefined.
Just as human authors review and polish their drafts for clarity and flow, the Holistic Agent takes a final pass over the full document. It smooths transitions, aligns tone and style, and resolves inconsistencies that arise when sections are written in isolation.
Critically, this agent also adapts the language and voice to match the user’s intent, whether formal, technical, or conversational, and generates the introduction and conclusion, framing the content with a clear purpose and takeaway. The result is not a stitched-together collection of paragraphs, but a unified document draft.
While today’s LLMs excel at generating fluent text, they fall short when it comes to producing long, structured, and factually grounded documents. Our multi-agent framework addresses these limitations by breaking the writing process into specialized stages and mirroring how expert authors work.
By combining focused research, structured planning, evidence-backed generation, and holistic refinement, this system delivers high-quality drafts that are coherent, complete, and ready for review. In document-heavy fields where accuracy, clarity, and speed matter, this approach turns LLMs from generic text generators into reliable writing assistants.
